The most common bottleneck we encounter in AI engagements isn't model capability. It's data access. Specifically, the enormous volume of organizational knowledge locked inside documents that are nominally available but operationally inaccessible.
A compliance library with 4,000 pages of policy documents. A procurement system with eight years of vendor contracts. A customer support archive with 200,000 historical tickets. A technical documentation repository that hasn't been indexed in three years. All of this knowledge exists. None of it is queryable in any meaningful way.
Document intelligence is the practice of making that knowledge operational.
What Document Intelligence Actually Encompasses
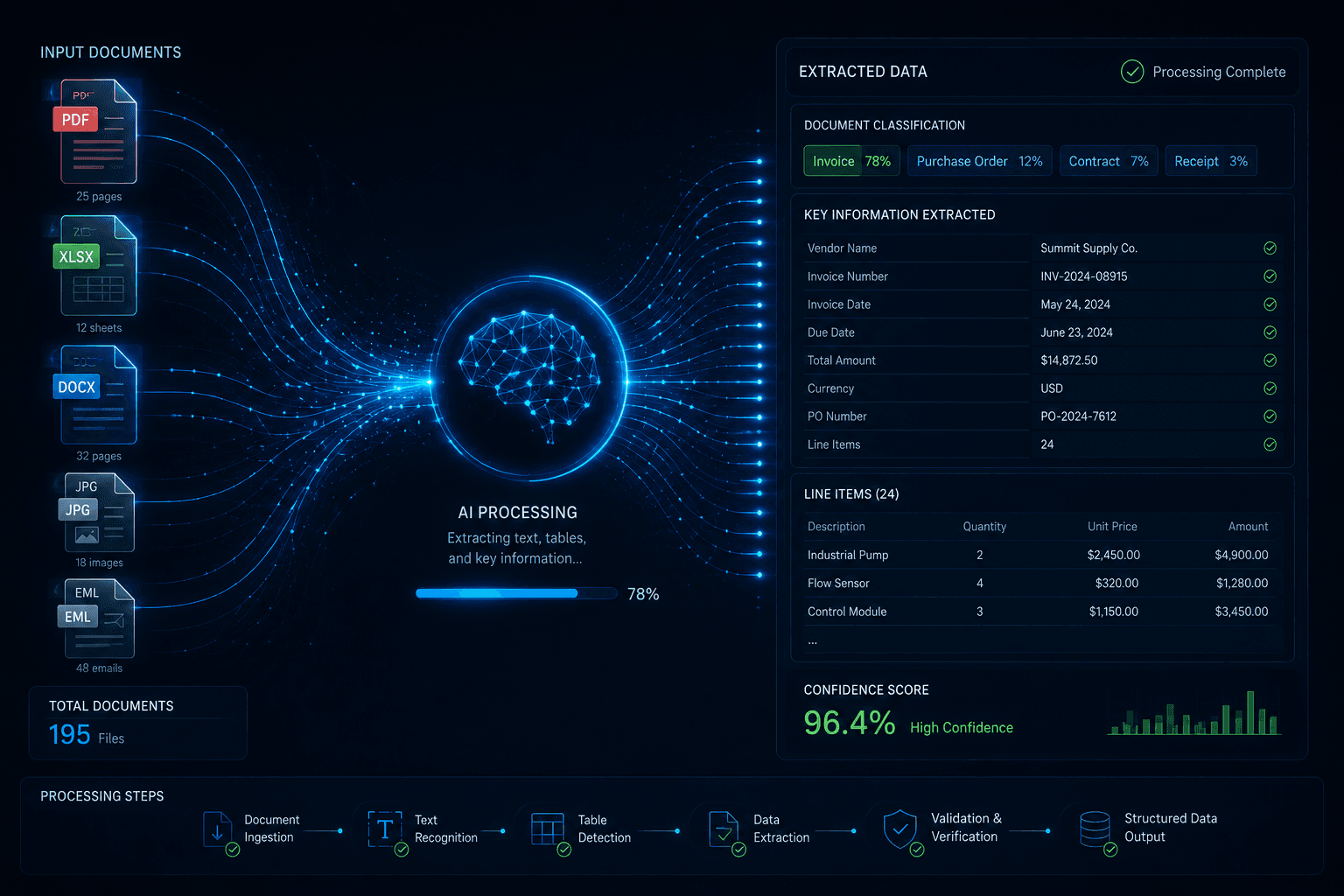
"Document intelligence" is sometimes used narrowly to mean OCR: optical character recognition, turning scans into text. That's a starting point, not the destination.
Production document intelligence systems operate at four levels.
Classification. Identifying what a document is: contract, invoice, regulatory submission, technical specification, support ticket. Classification happens at ingestion and enables everything downstream.
Extraction. Pulling structured data out of unstructured text: contract dates, parties, payment terms, clause types, product specifications, complaint categories. Extraction is where documents go from text to data, from something humans read to something systems can act on.
Comparison and gap analysis. Comparing documents against each other or against a standard: a new contract against your standard terms, a regulatory update against your existing policies, a vendor proposal against your requirements. This is where AI earns its keep. Tasks that would take a human analyst days can be completed in minutes.
Summarization and synthesis. Generating structured outputs from complex source material: executive summaries, compliance gap reports, risk assessments, key terms memos. The AI doesn't just retrieve. It reasons across the source material and produces something actionable.
The Technical Foundation
Document intelligence at scale requires several components working together.
Ingestion pipelines. Documents arrive through multiple channels: email attachments, file uploads, API feeds, EDI systems. A robust ingestion pipeline normalizes all of them into a common format, handles edge cases like corrupted files and unusual formats, and triggers downstream processing automatically.
Pre-processing and parsing. Raw documents need preparation before an AI model can work with them effectively. For scanned documents, that means OCR. For PDFs with complex layouts, it means structure-aware parsing that preserves tables, headers, and section relationships. For emails, it means separating attachments, signatures, and quoted text.
Semantic chunking and embedding. Parsed content is broken into semantically coherent chunks, embedded into vector representations, and indexed in a vector store. This enables semantic search: finding relevant content by meaning rather than keyword matching, across the full document library.
Model orchestration. Different document types and tasks need different model configurations. A contract comparison task has different prompt requirements than a regulatory gap analysis. Orchestration logic routes each task to the appropriate model and prompt template, manages context injection, and handles output formatting.
Human review and feedback loops. High-stakes extractions, whether financial figures, legal terms, or compliance determinations, require confidence scoring and human verification checkpoints. Corrections from human reviewers feed back into the system to improve accuracy over time.
Where Organizations See the Most Impact
Legal and compliance. Contract review, regulatory mapping, policy gap analysis. Organizations that previously needed legal or compliance staff to manually review every document can now run AI-assisted analysis that surfaces the issues requiring human judgment, while handling the structured review automatically.
Procurement and vendor management. Extracting and comparing terms across vendor contracts, tracking renewal dates, flagging non-standard clauses, monitoring compliance with preferred terms. What was previously a spreadsheet exercise becomes a live, queryable system.
Customer operations. Classifying and routing incoming customer documents, extracting relevant information for case creation, matching incoming issues to previous resolutions. Support teams that spent 20 minutes on intake and research for each ticket can shift that time to actual resolution.
Financial operations. Invoice processing, expense report review, financial document reconciliation. The extraction accuracy of modern document AI systems on structured financial documents is high enough for production deployment, with appropriate human oversight for exceptions.
Build vs. Buy
Off-the-shelf document AI products exist for well-defined, high-volume tasks: invoice processing, receipt scanning, form extraction. If your use case fits neatly into one of these categories, buying is often faster and cheaper than building.
Custom document intelligence systems become necessary when the document types are proprietary or complex, when the downstream integrations are bespoke, when the comparison or synthesis logic requires organizational context that generic products can't be trained on, or when data governance requirements prevent sending documents to third-party services.
Most of our engagements involve custom systems. The documents our clients need to process are specific to their operations, their regulatory environment, and their existing systems in ways that off-the-shelf products can't accommodate.
The Business Case
The ROI on document intelligence is typically straightforward to measure: analyst hours replaced by automated processing, reduced error rates on extraction tasks, faster compliance review. The less obvious benefit is scale. A document intelligence system doesn't get tired, doesn't have a headcount constraint, and processes the ten-thousandth document with the same accuracy as the first.
For organizations whose core operations depend on understanding and acting on documents, which is most organizations, that capability is foundational.