Large language models are trained on vast amounts of internet text. They know how to reason, write, and synthesize information at a remarkable level. But they don't know your internal policies, your product documentation, your historical contracts, or the procedures your team actually follows. Without additional grounding, they generate responses that sound right but reflect general patterns rather than your specific organizational reality.
That's the problem Retrieval-Augmented Generation (RAG) solves.
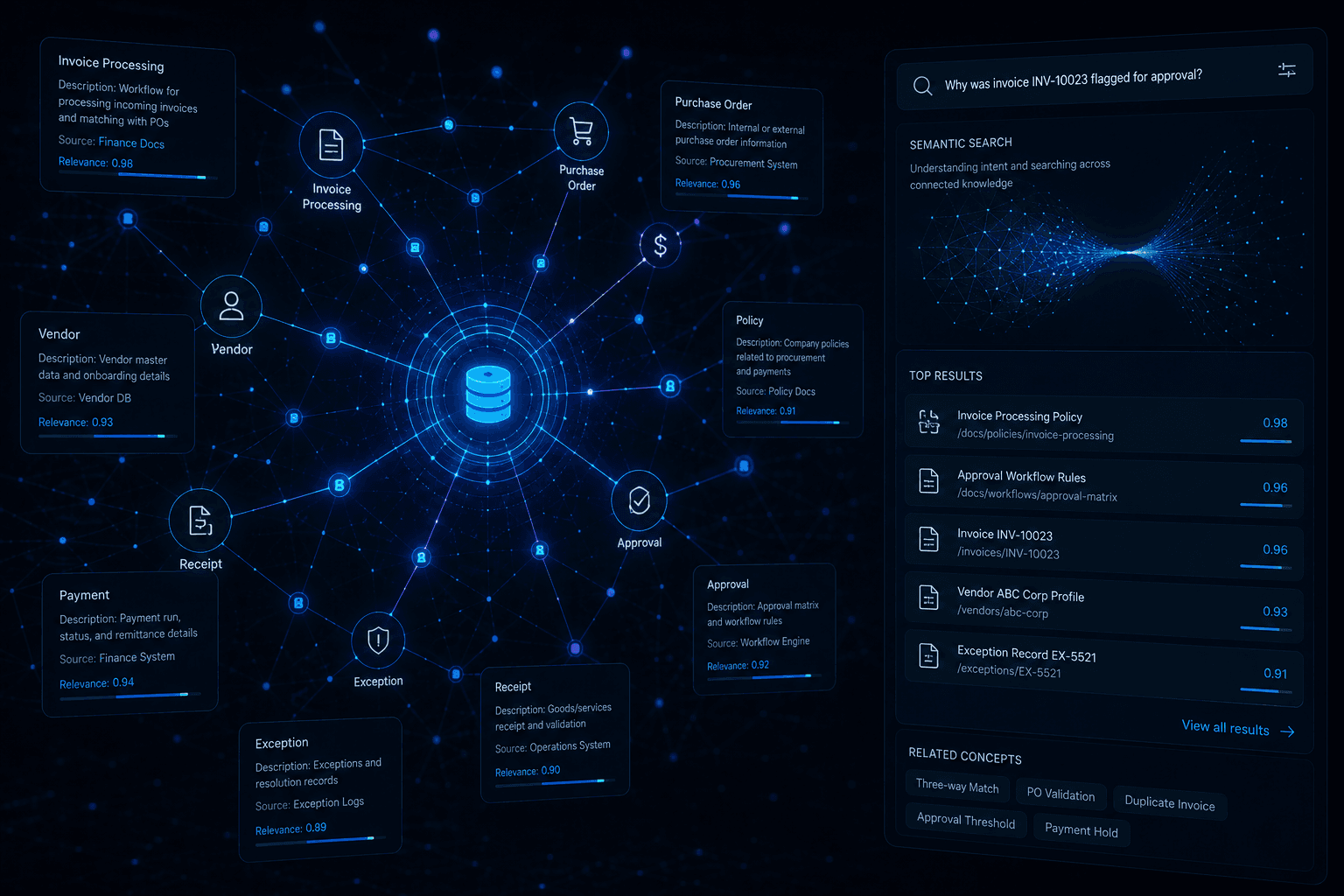
What RAG Actually Does
RAG is an architectural pattern, not a model or a product. It works in three stages.
Retrieval. When a query arrives, the system searches a pre-built knowledge store to find the most relevant pieces of organizational content. This search is semantic, not keyword-based. It understands meaning, not just matching words.
Augmentation. The retrieved content is injected into the model's context window alongside the original query. The model now has both the question and the relevant organizational knowledge it needs to answer accurately.
Generation. The model produces a response grounded in the retrieved content, not in its training data alone.
The result: an AI system that can accurately reference your specific policies, apply your actual standards, and synthesize your real organizational knowledge, without making things up.
Where RAG Lives or Dies
The quality of a RAG system depends almost entirely on the quality and structure of the underlying knowledge store. Building this correctly is where most implementations go wrong.
Source documents, whether contracts, policies, manuals, previous tickets, or product specs, are broken into chunks and converted into vector embeddings: mathematical representations of semantic meaning. These embeddings are stored in a vector database, which enables fast semantic search across millions of documents.
How you divide documents matters significantly. Chunks that are too small lose context. Chunks that are too large dilute relevance. The right chunking strategy depends on the content type and the query patterns of the use case.
A well-designed RAG system also tags each chunk with metadata: document type, date, department, version. A compliance query should retrieve compliance documents, not general HR policies. This filtering step is often skipped in early builds and causes serious quality issues downstream.
And the knowledge store is only as useful as it is current. Organizations that treat it as a one-time build and let it drift out of sync with actual policies discover that their AI system gives confidently wrong answers. Maintaining it requires ongoing ingestion pipelines and version control.
Where RAG Delivers the Most Value
Document review and comparison. RAG enables AI systems to compare a new document against a library of existing ones: flagging deviations from standard terms, identifying regulatory gaps, or surfacing relevant precedents. What would take a human analyst hours can be done in seconds.
Internal knowledge retrieval. Organizations accumulate enormous amounts of institutional knowledge in documents, wikis, and previous work products. RAG makes this knowledge queryable by anyone, not just those who happen to know where to look.
Customer and support systems. A support agent backed by RAG can instantly surface the most relevant documentation, previous resolutions, and product-specific configurations for any incoming query, eliminating research time and improving consistency.
Regulatory compliance. Mapping new regulations against existing policies, identifying gaps, and generating structured compliance reports, all grounded in actual regulatory text and your actual policy library.
What RAG Doesn't Do
RAG doesn't make an LLM infallible. If the knowledge store doesn't contain the answer, the model will either say so (good) or fill the gap with a plausible-sounding but incorrect response (bad). Designing the system to handle knowledge gaps gracefully, with appropriate uncertainty signals and human escalation, is just as important as building the retrieval system itself.
RAG also doesn't replace good prompt engineering. How you frame the context for the model, how you instruct it to handle conflicting information, and how you format the output all significantly affect the quality of results.
The Business Case
Organizations spend enormous resources on human effort that is fundamentally a knowledge retrieval problem: finding the right policy, comparing the right documents, surfacing the right precedent. RAG systems can perform that retrieval in milliseconds, at any volume, consistently.
The organizations seeing sustained operational improvements from AI are the ones that built RAG systems on their actual knowledge bases, rather than relying on a general-purpose model to somehow know their specific operations.